1 Abstract¶
This document proposes a relatively simple mechanism for using PanDA and Rucio to execute the Data Release Production across multiple sites while minimizing the transfer of data. Possibilities for future development are also described.
2 Background¶
The Data Release Production needs to run at multiple sites. 40% of the processing will be performed at the French Data Facility (FrDF) at CC-IN2P3. 25% of the processing will be performed at the UK Data Facility (UKDF), which may actually make use of resources at multiple physical locations in the UK. 35% of the processing, as well as the central control, will be hosted at the US Data Facility.
The USDF and FrDF will host 100% of the raw images. The USDF will host 100% of the published data products. It is expected that the UKDF will only host 25% of the raw images. The FrDF and UKDF will host some fraction of the published data products, but we should not rely on 100% of those products being present at either site. The files or objects composing these raw and published data products, along with temporary data products, are referred to here as “datasets”, corresponding with LSST Data Butler terminology. Each Butler dataset is typically composed of a single file that constitutes a usable scientific entity. In some cases, however, complex datasets with multiple components may be persisted as more than one file. Note that this somewhat conflicts with standard Rucio terminology, in which a “dataset” is a collection of files.
All sites will run the same Science Pipelines code, including middleware, using specifically-versioned binary artifacts retrieved from CVMFS. All sites will have a local Data Butler repository with Registry and Datastore using a PostgreSQL database. But the underlying batch execution system and storage systems may vary. In particular, the Datastore is typically expected to be an object store but might be a shared filesystem.
We are expecting to use Rucio to transfer data (raw, some intermediate, and published data products) from location to location.
We are writing a Replica Monitor service that monitors Rucio to determine when a replica of a dataset has been created and automatically ingests that dataset into a local Butler. Note that for this Replica Monitor to work, there must be sufficient metadata information either within the replicated file, replicated alongside, or perhaps registered as Rucio file metadata to allow Butler ingest. This metadata includes the Butler dataset type, dataId dimension values, and collection name. It also includes any provenance metadata pertaining to the dataset.
We are expecting to use the Batch Production Service (BPS) software in conjunction with PanDA to define and control the execution of processing workflows at each Data Facility. See below for more details on how this will function.
We are expecting to use a custom Campaign Management system to control the overall submission of workflows to Data Facilities and the sequencing of those workflows as part of the Data Release Production.
3 Existing Single-Site Processing¶
At a single site, an operator (or developer) provides a pipeline YAML file, a source Butler, and some configuration parameters to BPS. BPS accesses the source Butler to create a Quantum Graph (QG) describing the workflow to be performed, including all of the datasets to be used, both those already existing and those to be created.
An Execution Butler (EB) is generated from the Quantum Graph. This is materialized as a SQLite database that is provided to each job in the workflow; it holds all the relevant Butler Registry and Datastore information for the workflow, obviating the need to contact the source Butler for each job.
BPS generates jobs from the QG and submits them (using a plugin framework) to one of several available workflow systems. Each job retrieves datasets from or persists datasets to the underlying Datastore using pre-computed URIs in the EB. Depending on the type of URI (shared filesystem or object store), these datasets may be copied and cached locally on the worker node executing the job.
After execution of all the jobs in the workflow, the EB is merged into the source Butler, making the results available and preserving provenance.
In the near future (by the end of June 2023), the EB will go away, as the contents of its database will be part of the QG. This removes a generation step, but it does not change the need for a merge job.
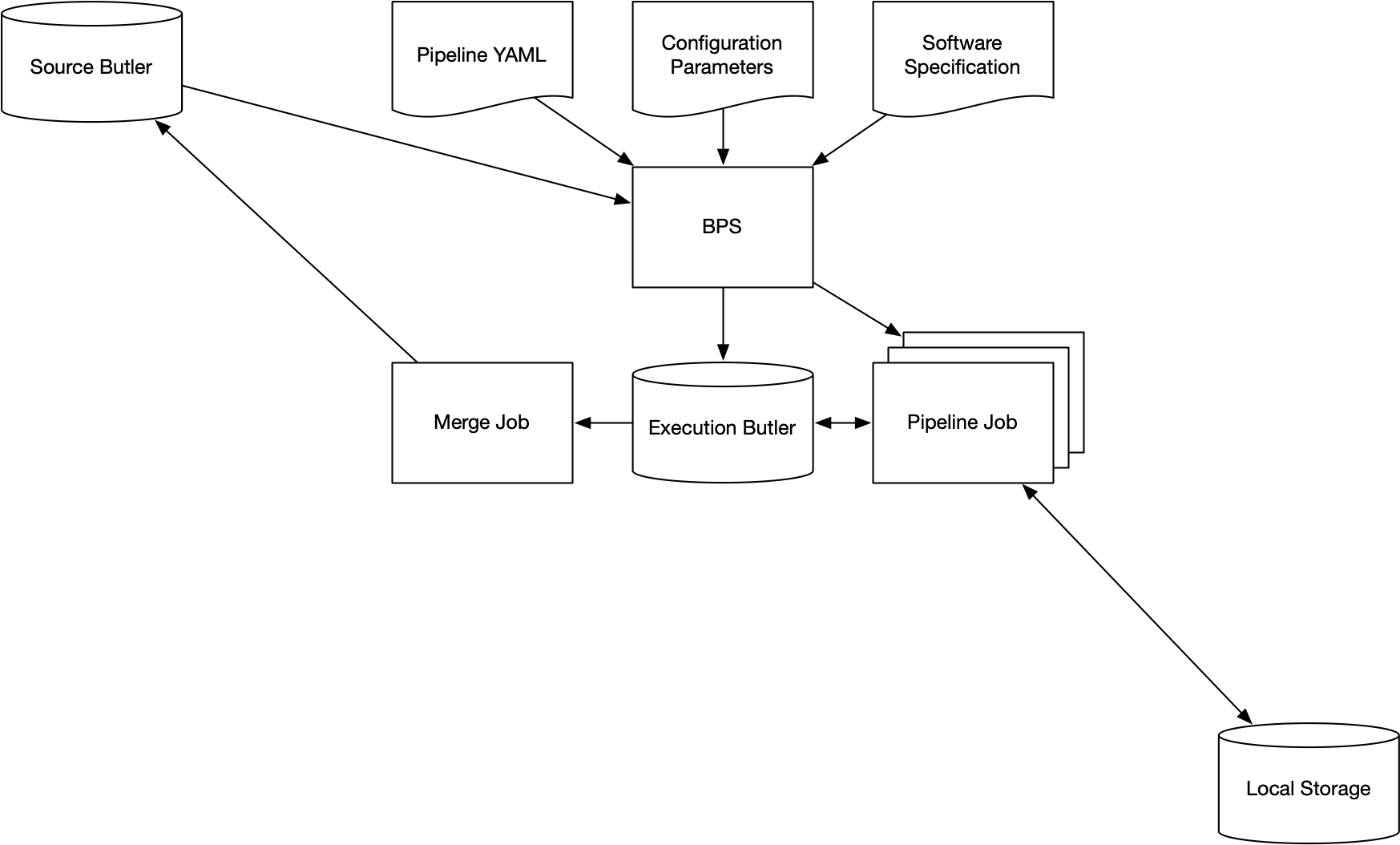
Figure 1 Single Site Processing with BPS.
4 Extension to Multi-Site Processing¶
The Butler Datastore tracks local datasets; it does not maintain knowledge of replicas in different locations. This is good, as it means that Rucio is the source of truth for which datasets are where.
Rather than trying to create a workflow that spans sites, we will insist that each workflow be executed at exactly one site. This simplifies the execution model, and it deterministically guarantees that potentially large temporary datasets are not implicitly transferred between sites. It will be the responsibility of Campaign Management to ensure that appropriate workflows are dispatched to appropriate sites and that all workflows constituting the Data Release Production are eventually executed at some site. Typically a region of the sky would be assigned to a site, and all workflows associated with that region would be directed to that site.
It is acknowledged that PanDA is typically used in a data-driven mode in which multi-site workflows are submitted with PanDA deciding where a given job should execute based on the location of prerequisite datasets. We are not using this mode because the Data Release Production is likely to use extensive temporary files derived from the Processed Visit Images (PVIs) that are shared between multiple coadd jobs within the same patch. Since these would be temporary, relatively large, and relatively numerous, they should not be replicated across sites nor regenerated for each coadd patch job.
Campaign Management could execute a modified BPS at the USDF, relying on it to generate QGs and workflows for remote sites, but it will be simpler and faster to execute BPS remotely at the local sites, as this requires no changes to the BPS code. The pipeline YAML file and configuration parameters will be passed to BPS, which will generate the QG and the workflow jobs based on the site-local Butler Registry and Datastore, which have all needed information about locally-present datasets. The QG will be stored locally as well as replicated via Rucio to the USDF as a provenance data product. The simplest way to execute BPS remotely is to submit it as a PanDA job (which in turn submits more PanDA jobs based on the QG).
Note that workflow submissions will use the PanDA BPS plugin and will submit jobs to local site queues but via the central USDF PanDA service. This will ensure that all jobs can be observed and tracked in one place.
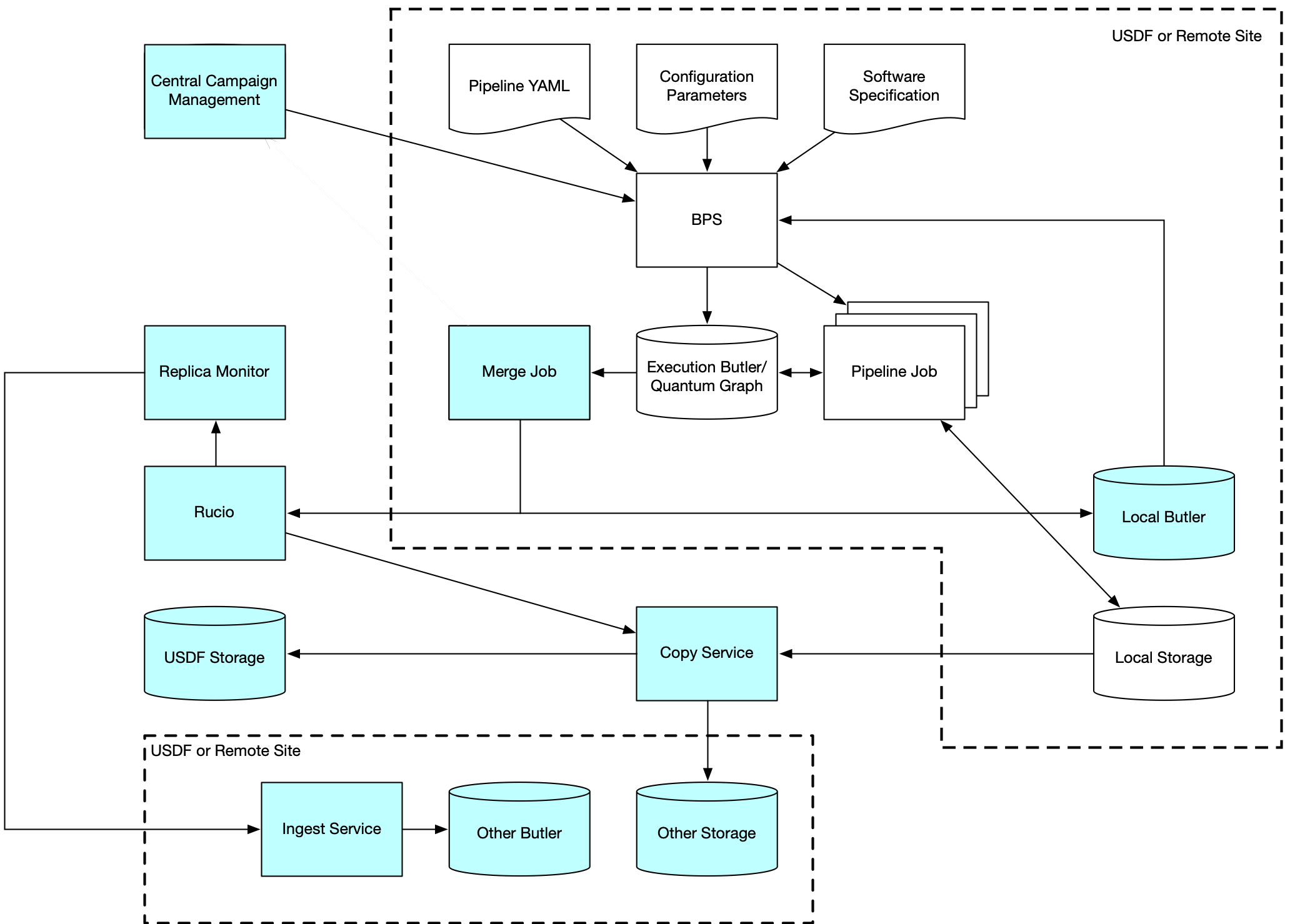
Figure 2 Multi-Site Processing with Local BPS. Blue items are added to the single-site processing diagram. Items in the dotted boxes execute locally at processing sites. Other items are centrally located at the USDF.
After the workflow is complete, the merge job merges the EB/QG into the local Butler at the site as usual, but code will be added that registers datasets of particular dataset types with Rucio. The dataset type list is composed of all published data products as well as any temporary data products that need to be globally distributed or globally summarized. This allows Rucio to replicate these outputs to the USDF and to any other location where they may be needed. The subscriptions needed to automate this replication are expected to use metadata items such as the dataset type and information from the data id, provided to Rucio at registration time, to make decisions as to proper destinations (including all Data Facilities for globally distributed datasets and the USDF for globally summarized datasets). These are mostly expected to be campaign-agnostic, although it may be prudent to allow per-campaign customization. The Replica Monitor then ingests the results into local Butlers at each site, making them available for use by following workflows and jobs.
Essentially this is using Campaign Management to do single-site workflow execution at each site independently, with Rucio replication of results.
A QG generation job at a local site should not be executed until all of its inputs are present. Since a local site cannot be certain of all the inputs that it should be receiving, it will be necessary to have an external synchronization to permit QG generation to take place. This is provided by the “step” structure of the Data Release Production. Each step produces one or more independent QGs that depend on outputs from prior steps but not the current step. As a result, if we wait for Rucio to be quiescent (no transfers remaining) after the execution of each step, we can then be assured that all inputs for the next step are available where they are needed. Re-execution of failed jobs or other recovery workflows will be site-local and so are assured that Rucio replication will not cause delays.
In this multi-site execution design, the BPS submission definition YAML will have to be customized for each local site, at a minimum specifying the compute site. But most Butler and Pipeline settings should be site-independent.
BPS maintains state in the local filesystem for its preparation, submission, reporting, cancellation, and restart functionality. While the central PanDA service allows an overall view of all jobs executing at any site, tools will probably need to be developed to remotely call BPS to report on its view of the state of each workflow and to control that workflow.
5 Current Status¶
5.1 BPS¶
A Rucio-registering merge job has not yet been written, but the code to do so has been demonstrated and integrated into the auto-ingest system for LSSTCam testing at SLAC.
5.2 Replica Monitor¶
Code has been written for this service to transform Rucio replica messages into Kafka messages with site-specific topics. Sites are setting up Kafka and MirrorMaker to enable those topics to be transferred. We plan to deploy the auto-ingest framework to ingest into the Butler upon receipt of the Kafka message, although it is possible that something simpler may work well enough in this non-realtime use case.
5.3 Campaign Management¶
This document will continue to be refined to provide sufficient information to Campaign Management to design the scripts and UIs needed to execute multi-site processing.
6 Future Improvements¶
6.1 PanDA staging¶
Today PanDA jobs are not provided with information about the local URIs of the datasets that are to be processed. This information is contained only in the QG and EB. But it would be possible to extract that information and provide it to PanDA, enabling it to stage the data from site-local storage to the worker node executing the job rather than having the Butler pull it from site-local storage. At this level, this is not really related to the multi-site problem, and it’s not clear that there is a significant efficiency advantage to pushing the data rather than pulling it.